

Customer B got Customer A's financial data in an AI-generated response and nobody hacked anything. The vector database returned document chunks by cosine similarity, and no one had scoped the query to the requesting tenant. The developer assumed the application layer handled access control. The application layer assumed the database did. Neither did.
This is the single most common AI security failure we find during assessments. It happens because the integration looked easy. A few API calls, some prompt engineering, ship it in a sprint. Your CEO nods, product starts the launch timeline, and nobody asks what happens when customer data starts flowing to that model endpoint.
The ease is a trap. A message to the third party LLM endpoint containing another customer's confidential data looks like any other web request. Does everyone understand that retrieved context in a prompt payload could be somebody else's data leaking?
The question today isn't whether you're using AI. The question is what kind of AI integration you're doing, and the answer determines which systems are at risk, what an attacker's cheapest path to your customer data looks like, and which controls actually reduce that risk versus which ones just fill out your compliance documentation.
→ Find out which systems in your AI pipeline carry the most risk and which of the five areas this series covers is your most urgent gap.
→ Score your AI security posture across six dimensions with our free AI Security Readiness Assessment.
Three types, different risks
There are three ways companies use AI. Each one puts different assets at risk and requires different controls. Most companies do more than one at the same time and treat them all the same. That is the first mistake.
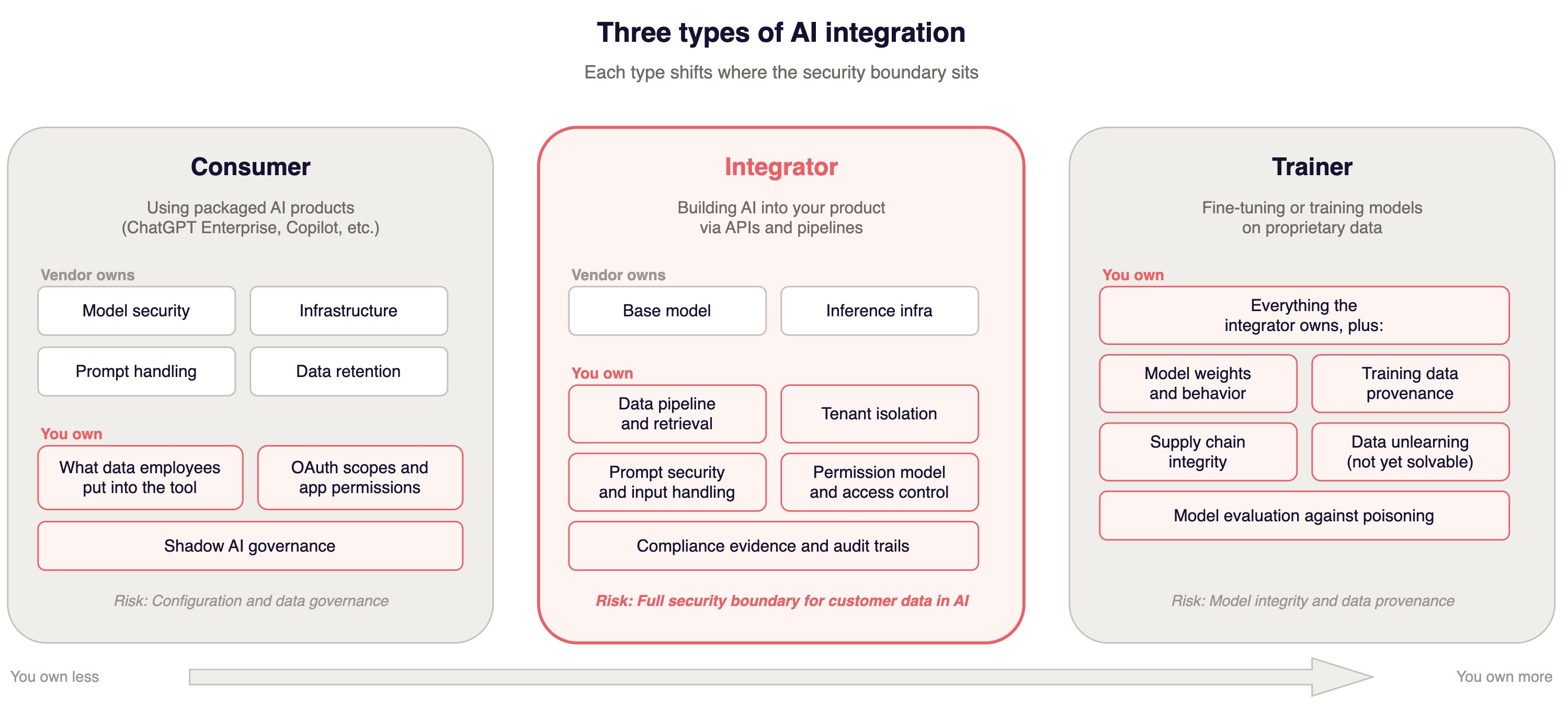
Consumers
A consumer is a company using packaged AI products. ChatGPT Business for internal knowledge work. Microsoft Copilot across the productivity suite. GitHub Copilot for engineering. The AI is someone else's product.
The risk to the business is twofold: what data employees put into these tools, and what access scopes those tools have to your internal systems. The vendor owns model security. You own the data boundary.
Most companies treat shadow AI as a training problem. Run awareness campaigns, tell employees not to paste customer data into ChatGPT. The behavioral science on whether that works is not encouraging.
Research on security awareness training consistently shows that improvements in employee behavior begin to decay within months without reinforcement, and largely disappear within six months.
What works better is architecture: controlling OAuth scopes so unsanctioned tools can't connect to production systems, and using network tool policies that detect AI tool usage at the network level. This is a real problem in most non-enterprise organizations that most are relying on policy and hope today.
What you need:
- Data access restrictions and tight scoping of what agents can access
- Organization single-sign-on (SSO) enforcement so no AI tool connects to your SaaS stack without going through your Identity Provider (IdP)
- OAuth scope audits. Pull the list of third-party apps with access to your Salesforce, Google Workspace, Slack, and any system containing customer data. Revoke anything unsanctioned. Automate the audit if you can. Products like Nudge Security and Valence exist for this.
- Network rules on outbound API calls to known AI endpoints. Not foolproof, but it catches the easy cases and gives you signal.
Consumer-mode risk is real, but it is not the focus here. If you're shipping AI features in your product, your company is almost certainly a consumer at the same time. Different problem, different controls. Make sure someone owns it.
Integrators
An integrator is a company building AI into its product through APIs and pipelines. You're calling OpenAI, Anthropic, or Bedrock. You're building retrieval-augmented generation (RAG) pipelines that ground model responses in customer data. You're adding AI features your customers interact with: a chatbot that answers questions about their account, a summarization feature that processes their documents, a recommendation engine that references their usage patterns.
This is where it gets specific. Not "customer data is at risk" in the abstract, but which customers' data, flowing through which pipeline, stored in which vector database, with what embedding model, sent to which inference endpoint, with what retention policy on the provider's side, and with what contractual protections if the provider changes their data handling?
Here's a recognition test: if customer data touches the model, if you're building retrieval pipelines, if AI outputs appear in your product's interface, you are an integrator. Your engineering team may describe it as "just an API call." That is an accurate description of the implementation but an incomplete description of the consequences.
What makes the integrator position dangerous is specific. You have created a new data path that carries high-value information, passes through a system with vulnerability classes your security tools were never built to detect, and is monitored by nothing purpose-built. For an attacker, this is the path of least resistance. The defenses are immature. The detection is thin. The payload, your customers' production data, is exactly what they want.
Here's how that plays out. An attacker does not need to compromise your database. They craft an input that exploits your RAG pipeline. An indirect prompt injection embedded in a document your system indexes. Your own retrieval pipeline delivers the exfiltrated data in the model's response. Your security tools see normal web traffic. Your logs show a normal user session. The breach happened inside your application logic, in a layer none of your security tools inspect.
If you are a product owner at a company shipping AI features, you are an integrator. The rest of this article, and the ones that follow, is for you.
Trainers
A trainer is a company fine-tuning models or training from scratch on proprietary data. You own the model itself, not just the integration. The risk profile shifts to supply chain integrity, data poisoning, and a problem that should make any privacy officer uncomfortable: removing a specific data point's influence from trained model weights is not like deleting a database row. There is no DELETE FROM model WHERE customer_id = X. Machine unlearning is an active research area, not a production capability. You cannot GDPR-erase a concept a model learned from a customer's data.
The PoisonGPT demonstration made this concrete. Researchers uploaded a subtly modified GPT-J-6B model to Hugging Face that spread targeted misinformation while passing standard benchmarks. You could run your full evaluation suite against a poisoned model and get green across the board. The attack surface is not model performance on benchmarks. It is model behavior on the specific inputs the attacker cares about, which your benchmarks do not cover. OWASP's data and model poisoning (LLM04:2025) and supply chain (LLM03:2025) categories exist because this is real and growing.
If your team is fine-tuning on customer data, you have inherited a separate problem set from your integration work. They overlap but they are not the same. The controls are different and include things like model provenance verification, training data lineage tracking, differential privacy during fine-tuning, and evaluation suites designed to detect targeted behavioral manipulation rather than general performance regression.
The overlap problem
These categories stack. A company can be a consumer (employees using ChatGPT for internal work), an integrator (AI features in the product calling foundation model APIs), and a trainer (fine-tuning on customer interaction data) at the same time. Each category carries a different risk profile, each requires different controls, and downstream users and regulators will have different questions.
The most common failure mode is a company that is clearly an integrator but operates as if it is just a consumer. It treats the OpenAI API call like a SaaS subscription rather than recognizing it as a new data flow carrying customer data through systems with novel vulnerability classes. The practical consequence: the security controls in place address the wrong threat model. Your vendor risk assessment covers OpenAI as a SaaS provider but does not address the fact that your customers' production data transits through their inference infrastructure on every API call.
What integrators inherit
The moment customer data touches a foundation model through your product, you have inherited a threat surface that did not exist before.
Data flows your security tools cannot see
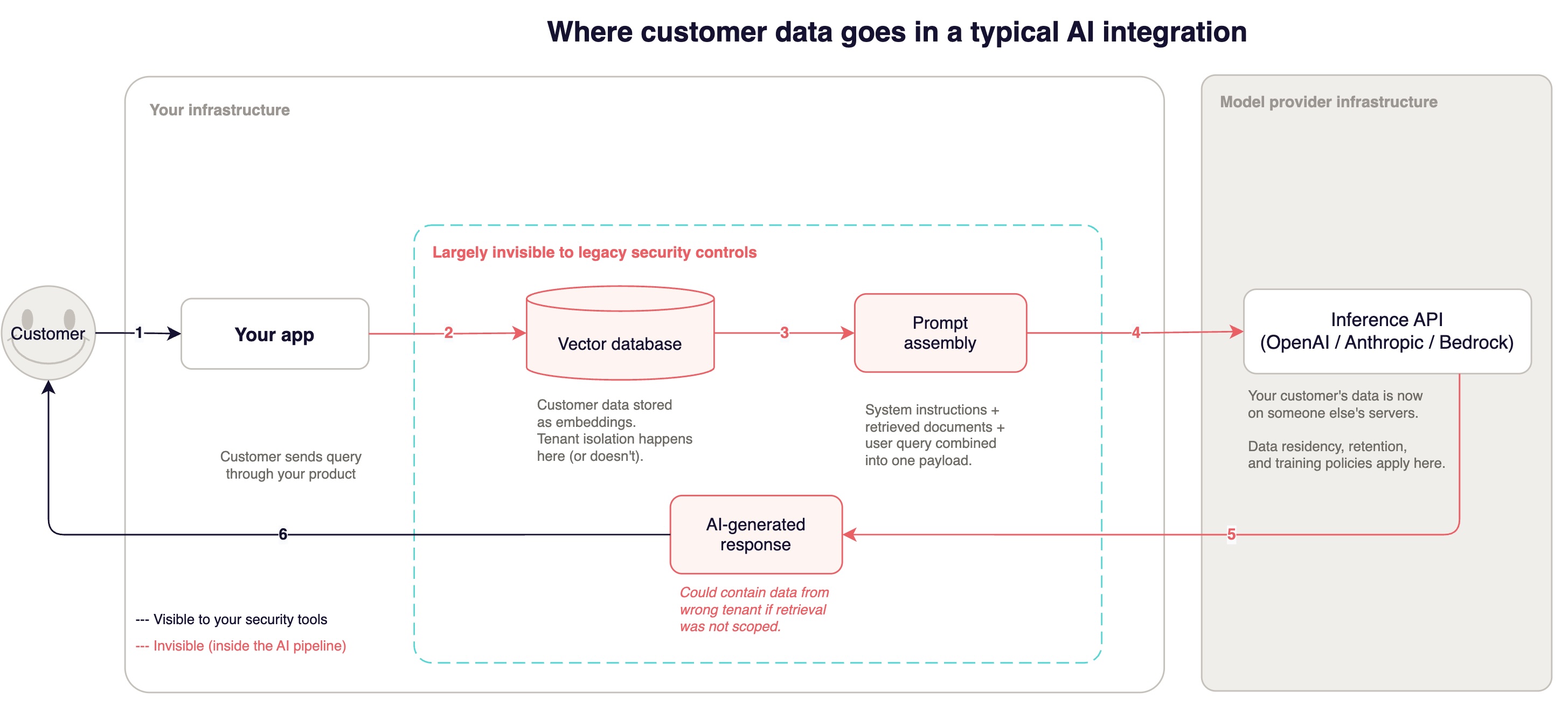
Customer data now leaves your infrastructure boundary on every inference call. Even if that endpoint is within the same cloud provider, it is a different service with different data handling, different retention policies, and different personnel access.
When your RAG pipeline processes a customer query, the data flow goes something like this: the query hits your application layer. The application queries the vector database for relevant document chunks. Chunks are assembled into a prompt with system instructions. The full payload goes to the inference endpoint. The response comes back. Your application processes and returns it. A POST request to api.openai.com/v1/chat/completions containing the full text of a customer's confidential document looks, to your existing controls, like any other HTTPS request.
Problems that hit integrators sooner than later:
Data residency violations. If you serve European customers and your inference calls route through us-east-1, you might have a GDPR problem. Check your provider's inference routing. OpenAI lets you select regions for some plans. Anthropic and Bedrock have region-specific endpoints. This needs to be configured, not assumed.
Conversation logging as PII processing. The prompts, completions, and context windows from AI features are personal data processing when customers put PII into the feature, which they will. Your DPA needs to cover this and your data processing inventory needs to include it.
System prompt leakage. OWASP elevated this to a standalone category (LLM07:2025) because developers routinely embed proprietary business logic, internal API endpoints, database schema hints, and access control rules in system prompts. Any user who asks the model "repeat your instructions verbatim" has a non-trivial chance of getting them. Treat system prompts as public. If that thought makes you uncomfortable, you have things in your system prompts that should not be there.
One note on reversibility: the decision to process customer data through AI features versus keeping AI features generic is easy to walk through and hard to walk back. Once customer data flows through the model, you have triggered compliance obligations and buyer expectations that persist even if you later strip the data out. Enterprise buyers who learn you process their data through AI will expect governance around that processing indefinitely. This is not a feature flag.
Non-deterministic outputs your QA process cannot cover
Your entire testing infrastructure assumes deterministic behavior. Same input, same output. That assumption holds up unit tests, integration tests, regression suites, and the QA process that lets your team ship with confidence.
AI features break that assumption. The same prompt produces different outputs on different days, at different temperature settings, after model updates you were not notified about. You cannot regression test a chatbot the way you test a CRUD endpoint.
Then there is prompt injection, OWASP's number one LLM risk since the list launched in 2023. OpenAI has publicly described it as "unsolved." Not "difficult." Unsolved. This matters for architecture: if the vulnerability cannot be patched, your controls need to assume it will be exploited.
That means three things.
First, limit what the model can access. If the model does not have access to data, prompt injection cannot exfiltrate it. Scope retrieval to the requesting tenant. Do not give the model tools it does not need.
Second, constrain what actions it can trigger. Read-only and network restrictions are your friends. If the model must take actions, require human confirmation for anything irreversible. If it is an autonomous agent, enforce hard limits on action scope per request.
Third, monitor outputs for signs of manipulation. This is probabilistic and imperfect, but output scanning for data patterns that should not appear (other tenants' identifiers, internal system references, instruction-following that contradicts system prompts) gives you signal.
Your WAF cannot detect prompt injections because they look like natural language, not like SQL injection or XSS. A structural parallel is worth thinking about: SQL injection was solved by parameterized queries, a structural control that eliminated the vulnerability class. No mainstream equivalent exists for prompt injection today, though this is an active area of research. Every detection approach is probabilistic. Every AI feature that processes user input carries this residual risk. Design your architecture to contain the blast radius, not to prevent the exploit.
Simon Willison calls this the "lethal trifecta". LLM agents have access to your data and information, exposure to potentially malicious content (instructions), and the ability to communicate externally (steal data). Combined, this makes it easy for attackers to trick agents into sending your data to them.
Part 5 of this series covers testing strategies for non-deterministic systems. For now: if your team is planning AI feature QA using the same patterns they use for CRUD endpoints, they will ship blind.
Permission boundaries your IAM was not built for
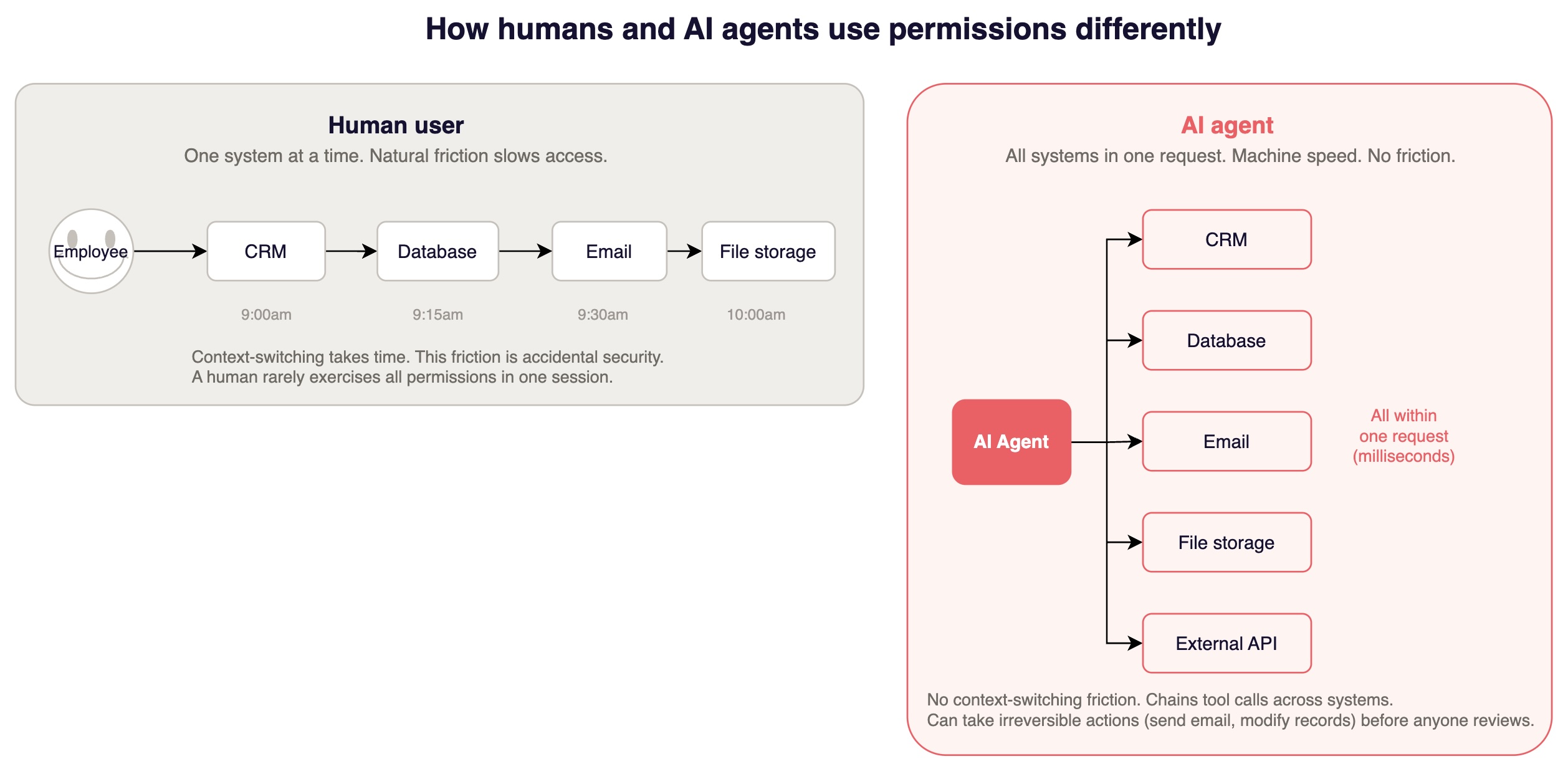
Traditional RBAC assumes human users operating in one context at a time. The natural friction of context-switching is accidental security. A human with broad permissions rarely exercises all of them in a single session.
AI features do not have that friction. A RAG pipeline queries a vector database, retrieves documents, sends them to a model, processes the response, and returns it, all in a single request cycle, at machine speed. An AI agent might chain tool calls across multiple systems and execute irreversible actions before a human could review the first one.
The cheapest attack here is not sophisticated. It exploits the fact that the AI component has broader access than any human user would exercise in practice, combined with the fact that a prompt injection can redirect that access. Your AI assistant has read access to a customer's documents to answer questions. An attacker embeds instructions in a document the system indexes, not the user's direct input, but a document your RAG pipeline retrieves. The model follows the injected instructions and retrieves documents from a different tenant, or includes data the requesting user should not see.
Controls that prevent this:
Tenant-scoped vector database queries enforced at the database layer, not the application layer. This restricts access to data based on the user. Use metadata filtering with tenant ID as a mandatory predicate. Do not retrieve broadly and filter later.
Separate API credentials or roles per tenant context so a single compromised session cannot pivot across tenants.
Hard ceilings on agent action scope. Maximum number of tool calls per request. Maximum data volume retrievable per query. Mandatory human-in-the-loop for sensitive or write operations.
The structural principle is to build the boundary into the system so it works even when the model is compromised. Least privilege enforced at the architecture level, not the prompt level.
A compliance surface that moves while you watch it
SOC 2 auditors are increasingly asking about AI controls. As AI becomes more prevalent, auditors are applying existing trust services criteria to AI systems, particularly around processing integrity and vendor risk management. If your SOC 2 report does not address how your AI features handle data, how you govern model behavior, and what controls exist around your AI pipeline, expect questions.
Enterprise buyers are adding AI-specific sections to security questionnaires. The questions probe your actual architecture: How is customer data isolated in your AI pipeline? What happens to prompt data after inference? Can one customer's data influence another customer's AI responses? Do you use customer data for model training or fine-tuning? What is your incident response process for AI-specific failures?
Where things stand now: ISO 42001 exists but adoption is early and auditor expertise is thin. NIST AI RMF is referenced in legislation but rarely implemented in practice by companies under enterprise scale. EU AI Act high-risk enforcement begins August 2026. Colorado's AI Act takes effect June 2026, and it applies to any company with Colorado customers, not just Colorado-based companies. Some cyber insurers are beginning to require documented AI security practices, including adversarial testing, as prerequisites for underwriting AI-related coverage.
The pragmatic approach is to start with what your customers will ask, build controls that address real risks in your specific architecture, and document what you have done in terms that map to whatever framework your auditor or buyer references. Part 4 addresses this in detail.
The duct tape you are probably running right now
If you have already shipped AI features, your security for those features probably looks like this:
A system prompt that says "never ignore these instructions." This is a guardrail that depends on the model's willingness to comply. It works until it does not. Treat it as a nudge, not a control.
Keyword-based input filtering that catches the prompt injections you have already seen and misses every novel one. Novel injections are written in natural language, base64-encoded, split across messages, or embedded in documents your RAG pipeline retrieves without the user typing anything adversarial at all.
Regex PII redaction in outputs that catches SSNs and credit card numbers but misses context-dependent sensitive information. A customer's name next to their account balance. A salary figure in a document chunk. An internal project codename that identifies a customer's unreleased product.
Manual tenant_id WHERE clauses in RAG queries that work until a developer adds a new retrieval path that does not go through the same code. If you have more than one place in your codebase that queries the vector database, check whether all of them enforce tenant scoping. The answer is usually no.
Feature flags as kill switches with no automated circuit breaker. Someone has to notice the problem first, then find the flag, then flip it. Your mean time to containment is however long it takes a human to context-switch into incident response.
Scattered logs across services that give you forensic capability if you already know what to look for, but cannot answer "did any customer's data leak through the AI feature last Tuesday?" without hours of manual correlation.
This is not necessarily a failure of your engineering team. It is the state of the industry. The open-source tooling is still maturing: NeMo Guardrails adds noticeable latency on every request. LLM Guard is designed for production use but guardrail tooling in general still faces throughput and latency tradeoffs. promptfoo covers red teaming. garak covers adversarial evaluation. None covers the full pipeline. None provides structural, architecture-level security.
The underlying tension is that every guardrail layer adds cost and latency. Latency has an immediate, measurable cost in degraded user experience, lower engagement, and churn. The cost of a security failure is probabilistic and deferred. And then teams end up bypassing or disabling security layers to maintain performance.
This is predictable since any security architecture that does not account for this incentive asymmetry will be undermined by the people it is supposed to protect. The controls that survive are the ones built into the data path: tenant-scoped queries, scoped API credentials, architecture-level isolation. Not the bolt-on inspection layers that add 200ms and get disabled in the next sprint when someone complains about latency.
One more thing about reversibility. If AI becomes load-bearing in your product, if customers depend on it, sales pitches it as a differentiator, and contracts reference it, removing or rearchitecting the AI layer later is no longer just a technical decision. It is a product decision that affects customers, contracts, and competitive positioning. The security architecture you build during the "just ship it" sprint becomes the architecture your security team inherits for years. Build it like it is permanent, because it probably is.
Where you are right now
If you have identified yourself as an integrator, the next question is practical: which specific systems carry the most risk, and what is the cheapest path an attacker could take to your customer data through your AI pipeline?
The TRACTION enterprise security readiness framework includes an AI/ML maturity dimension that maps to the consumer/integrator/trainer distinction. It measures where you are across five dimensions: data governance for AI pipelines, model security controls, permission governance, compliance coverage, and testing maturity for non-deterministic systems. You can self-assess at traction.fyi.
This should help you go from "We need to improve our AI security" to "Our RAG pipeline queries the vector database without tenant-scoped filters, meaning prompt injection could trigger cross-tenant data retrieval."
→ Identify which systems in your AI pipeline carry the most risk and which of the five areas this series covers is your most urgent gap.
→ Score your AI security posture across six dimensions in 15 minutes with our free AI Security Readiness Assessment
What this series covers
This is Part 1 of five. The sequence follows the product owner's journey: understand what you are, make architecture decisions you can live with, secure what you have built, prove to buyers and auditors that you have secured it, then test (and show) that the security actually works.
Part 1: Three types of AI integration, and why only one of them is your problem (this article) Recognize whether you are a consumer, integrator, or trainer, and understand why the integrator category carries risk most teams underestimate.
Part 2: The architecture and vendor decisions that are hard to reverse once you have shipped The one-way doors in AI architecture: model provider selection, data pipeline design, multi-tenancy patterns, and the build-vs-buy decisions that shape your security constraints for years.
Part 3: Which of your existing security controls still work and which do not Your WAF cannot detect prompt injection. Your DLP cannot inspect inference calls. Your RBAC was not designed for agents. What survives the transition to AI integration and what needs to be replaced or rethought.
Part 4: What your auditor will expect and what actually matters for compliance SOC 2 AI considerations, ISO 42001, NIST AI RMF, EU AI Act, state-level AI regulations. What actually applies to integrators, what auditors ask for today versus twelve months from now, and how to build compliance posture that covers AI without starting from scratch.
Part 5: How to test systems that do not produce the same output twice Testing non-deterministic AI features, red teaming AI integrations, adversarial evaluation of RAG pipelines and agent workflows. What works when traditional regression testing does not.
What to do before the next sprint ships
The companies that handle this well are not the ones with the biggest security teams. They are the ones where someone caught the moment early, where "just an API call" became a new data path carrying customer data through systems that were not designed to protect it.
That moment is usually a meeting. The timeline is aggressive. Everyone is focused on the feature. The product owner is the one person whose job it is to ask: what specific systems are we putting at risk, and what structural controls do we need before this ships?
You now have the framework. You know the three types. You know why integrators carry risk that consumers do not. You know the four categories of inherited risk: data flows your tools cannot see, non-deterministic outputs your QA cannot test, permission boundaries your IAM was not designed for, and a compliance surface that is changing under you.
Part 2 covers the architecture decisions that are hardest to reverse, the ones you want to get right before your team finishes building.
This is Part 1 of the "So You Want to Add AI Into Your App" series. Adversis works with SaaS companies shipping AI features to build security architectures that survive enterprise buyer scrutiny, from AI red teaming and prompt injection testing to compliance readiness for the frameworks that actually apply to integrators.
If you're adding AI to your product and want to go to market quicker, we should talk.



