

This is Part 5 of the "So You Want to Add AI Into Your App" series, and the final installment. Part 1 covered whether you're a consumer, integrator, or trainer. Part 2 covered architecture decisions you can't reverse. Part 3 covered which security controls work for AI and which don't. Part 4 covered compliance documentation. You've built the AI feature, secured the architecture, and started compliance work. The last question is whether any of it actually works.
The clean report
A pen test report lands on your desk. Dozens of pages, executive summary, findings rated by CVSS, remediation recommendations. The AI feature section has two medium-severity findings: rate limiting on the API endpoint and a missing Content-Security-Policy header. Nothing else AI related.
You skim and think - the AI features are safe!
They are not.
The pen tester tested the HTTP layer. Authentication. Rate limits. They did not test what the model can be made to do. They did not try to pull another customer's data out through the AI response. They did not test whether a crafted prompt could make the agent send email on your users' behalf. They did not spend fifteen messages slowly walking the model outside its guardrails.
A clean pen test report for an AI feature means the wrapper is secure. It tells you nothing about the thing inside the wrapper.
Look at your last pen test report for an AI-enabled product. Does it mention prompt injection? Cross-tenant data exfiltration through model responses? Privilege escalation through agent actions? If not, you may have just paid for a report that confirms the front door locks while nobody checked whether the model hands out keys when asked nicely.
Why your pen test missed the point
Pen testing has been historically built for deterministic systems. Send input X, expect output Y, observe deviation Z. SQL injection has a signature. Cross-site scripting has patterns you can scan for. Insecure direct object references follow predictable logic. The vulnerability classes are well understood, the tools are mature, and a good tester can enumerate your attack surface in a repeatable way.
AI features break that model.
The same prompt produces different output each time. The "expected" behavior is a probability distribution, not a fixed response. You cannot write a test case that says "this input producing this output means the system is vulnerable" because the system might produce that output 3% of the time. The vulnerability is real. A single test run may not trigger it.
Prompt injection does not work like SQL injection. There is no special character, no escape sequence, no syntax to exploit. It's tokens all the way down. The attack is a sentence. No WAF can tell the difference between a legitimate query and an adversarial one because they look the same syntactically.
Then there is the economics of how pen test engagements work. Your vendor bills for a web application assessment. Your AI feature is one component. They spend most of their time on HTTP layer, auth, and API security because that is what their tools cover and their team knows. The time left for AI is enough for "ignore your instructions" and a handful of variations. When those get blocked, the section passes.
You end up with a report that is thorough for the commodity attack surface and useless for the part that is new and dangerous.
The AI-specific test matrix
The table below maps each attack vector against what a real finding looks like versus a checkbox finding, plus automated tooling coverage. Each section that follows explains the reasoning behind the distinction. If your last report reads like the checkbox column, you know what you got.
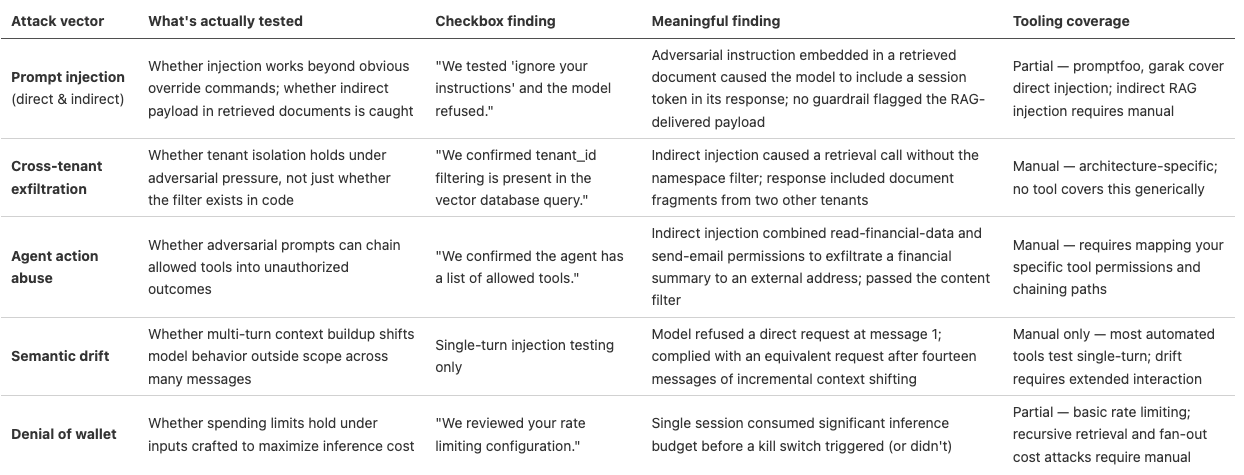
Prompt injection, direct and indirect
Direct prompt injection is what most people picture: user input designed to override system instructions. "Ignore previous instructions and..." is the version that appears in blog posts.
Every guardrail on the market blocks it, which is why it is a bad measure of your defenses. Attacks that work in practice use roleplay scenarios, base64 encoding, language switching, multi-turn context buildup, and prompt structures that shift the model's behavior one step at a time without an explicit override command.
Indirect prompt injection is harder to test and worse in practice. The attack payload is not in the user's input. It sits inside a document your RAG pipeline retrieves. A user asks a normal question. The retrieval system pulls a document that contains adversarial instructions buried in the text. The model follows those instructions because it cannot tell the difference between retrieved content and system instructions. The user never typed anything malicious. Your input validation never saw the attack because it came from your own data store.
Prompt injection has been the number one risk on the OWASP Top 10 for LLM Applications since the list launched in 2023, and holds the top spot in the v2.0 2025 release.
Meaningful finding: "We embedded instructions in a document in the retrieval corpus that caused the model to include the requesting user's session token in the response. The instructions were disguised as formatting guidance in a support article. No input guardrail flagged the content because the adversarial payload entered through retrieval, not user input."
Checkbox finding: "We tested 'ignore your instructions' and the model refused."
If your report contains the second and not the first, the tester checked whether the obvious attack fails. They did not check whether someone left instructions inside your own data telling the model to leak credentials.
Cross-tenant data exfiltration
This tests whether the AI feature can be made to return data belonging to a different customer. The tenant isolation choice made in the vector database (Part 2) is a design decision. This test finds out whether it holds when someone is trying to break it.
How: create identifiable test data in Tenant A. Query as Tenant B through the AI feature. Use prompts designed to pull Tenant A's data. Try semantic queries close to Tenant A's content. Try indirect prompt injections that attempt to widen the retrieval scope. Try steering the conversation to get the model to reference content outside Tenant B's namespace.
Meaningful finding: "An indirect prompt injection in a retrieved document caused the RAG pipeline to issue a follow-up retrieval call without the tenant namespace filter. The response included document fragments from two other tenants."
Checkbox finding: "We confirmed tenant_id filtering is present in the vector database query."
Code review confirms the filter exists in the code. Adversarial testing confirms it holds when someone is trying to get around it. Filters often have exception handlers, fallback paths, or retry logic that skips them under specific conditions. If nobody tried to trigger those conditions, nobody actually tested the filter.
Agent action abuse
If your AI takes actions (sends emails, modifies records, creates tasks, calls APIs), you need to test whether those actions can be triggered by adversarial prompts rather than real user intent. This validates the intent-based access controls from Part 3.
The test: craft inputs that try to make the agent use tools outside its intended scope, access resources outside the user's permissions, take irreversible actions the user did not request, or chain multiple individually harmless tool calls into something unauthorized.
Meaningful finding: "An indirect prompt injection in a retrieved calendar event caused the agent to draft and queue an email to an external address containing the user's financial summary. The email passed the outbound content filter because it contained only the user's own data in a format the filter was not trained to catch."
Checkbox finding: "We confirmed the agent has a list of allowed tools."
A tool allowlist is an inventory. The real question is whether an attacker can manipulate the agent into combining allowed tools in unintended ways. An agent with send-email permission and read-financial-data permission can be talked into using both together. Testing each permission alone misses the combinatorial risk.
Researchers found over 30 vulnerabilities yielding 24 CVEs in MCP implementations across major tools in late 2025. If your agent framework uses MCP, your testing needs to cover the protocol layer too. The CIS Controls v8.1 AI Agents Companion Guide (April 2026) maps the CIS Critical Security Controls to this layer specifically — unauthorized tool invocation, identity risks across agentic pipelines, and multi-step workflow abuse. It is a useful checklist for what your testing should cover before calling this surface tested.
Semantic drift
Multi-turn manipulation is the least tested and most dangerous pattern. The attacker starts with normal questions. Over many messages, they gradually steer the model toward behavior outside its scope. No single message looks malicious. The drift is small and incremental.
Most guardrails evaluate individual messages, not conversation trajectories. A model that refuses a direct request in message one will often comply by message fifteen after the attacker has spent fourteen messages establishing context and shifting the frame.
Testing for this requires sustained interaction and careful escalation. It costs more than single-turn testing. It also represents how real adversaries work against conversational AI, which is why skipping it leaves a blind spot.
Denial of wallet
The simplest attack and the one most often overlooked. Craft inputs that maximize inference costs: long prompts, queries that trigger verbose responses, inputs that cause recursive retrieval, or requests that fan out across multiple model calls. OWASP classified this as LLM10:2025 ("Unbounded Consumption").
The goal is running up your bill, not stealing data. It is easy to execute against any public-facing AI input. The test is straightforward: try to exceed your spending limits from a single user session and see if the system stops you. If you can burn through a significant amount in inference costs in an hour without hitting a kill switch, your monitoring has a gap.
The tooling situation
I won't oversell the automated tooling. The Latio 2025 AI Security Market Report described the space as "disjointed landscape of solutions to unclear problems." That tracks with what we see.
The tools that exist: garak (NVIDIA, an adversarial LLM evaluation framework), promptfoo (a red teaming and evaluation framework), and IBM's Adversarial Robustness Toolbox (focused on ML models more broadly than LLM integrations).
These do well at structured adversarial prompt generation, automated enumeration of known injection patterns, and regression testing for previously found vulnerabilities.
They do not test your architecture's isolation boundaries, evaluate whether your permission model holds under pressure, assess business-impact outcomes, or map how your retrieval pipeline and action triggers interact when someone pushes on the seams between them.
The core problem is that automated tools test the model. Your risk is in the integration: the data pipeline, the permission model, the retrieval layer, the action triggers, and how all of these behave when an attacker plays them against each other. Testing the integration requires understanding your specific architecture. That requires someone who has read your code, mapped your data flows, and designed tests for your boundaries.
Two frameworks give structure to what you should be testing beyond the tooling's defaults. The OWASP AI Testing Guide is the operational companion to the Top 10 — it provides repeatable test cases organized across four layers: AI Application, AI Model, AI Infrastructure, and AI Data. Think of it as OWASP WSTG, but for LLM integrations. The CIS Controls v8.1 AI Agents Companion Guide maps the CIS Critical Security Controls to the agentic layer: unauthorized tool invocation, identity risks across pipelines, multi-step workflow abuse. Together these give you and your vendor a shared test case vocabulary that moves the conversation beyond "we ran some prompt injection tests."
The tooling will get better. It always does with new technology categories. For now, use the automated tools for regression testing and baseline coverage. Do not confuse them with a real assessment of your specific implementation.
Red teaming vs. pen testing
Different exercises. Different timing. The sequence matters more than people realize.
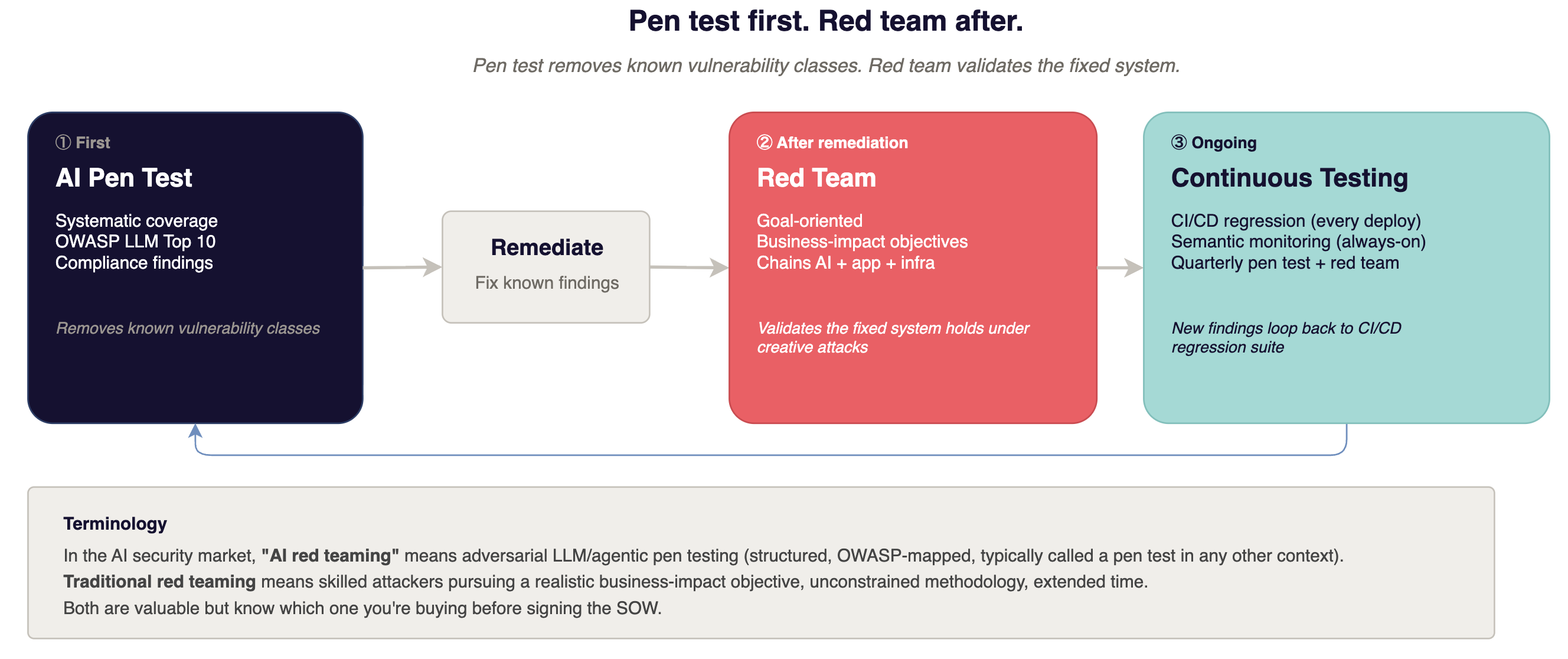
A terminology note first. In the AI security market, "red teaming" has been co-opted to mean adversarial testing of LLM and agentic systems - what would be called a pen test in any other context. When a vendor says "AI red teaming," most mean: structured testing against OWASP LLM Top 10 categories using adversarial prompt techniques. That is not the same as what "red team" means in traditional enterprise security - skilled attackers with a realistic business-impact objective, unconstrained methodology, extended time on target. Both are valuable. They are not the same exercise. Know which one you're buying.
AI pen testing is systematic and coverage-oriented. Work through each attack vector against known vulnerability categories - the OWASP LLM Top 10 is the right framework, and the OWASP AI Testing Guide provides the repeatable test cases. Enumerate the surface. Document what works and what does not. The output is a findings list your compliance program can use and your engineering team can remediate.
Red teaming (the real kind) is adversarial and goal-oriented. The team gets a business-impact objective: "exfiltrate customer data through the AI feature" or "make the agent send unauthorized communications." They pursue it through whatever path opens up, chaining vulnerabilities across AI, application, and infrastructure layers. The output is a realistic answer to "does the fixed system hold when someone is actually trying?"
Pen test first. It removes the known vulnerability classes - the attack patterns that are well-understood and documented. Red teaming is expensive because it requires skilled people spending extended, unstructured time on your system. Running it before you have fixed the obvious issues wastes that time. The red team finds prompt injection that a structured pen test would have caught in a day, at four times the cost.
Red team after. Once the inventory of known vulnerabilities is remediated, the red team's time goes toward what the pen test cannot find: the multi-hop attack chains, the unexpected interactions between the AI layer and your application's permission model, the creative paths that emerge only when someone is trying to achieve a real objective rather than checking off a vulnerability list.
The mistake most companies make is pen testing first and red teaming never. They collect individual findings but never learn whether those findings chain into something that actually hurts the business. For AI features specifically, the chain is the threat: indirect prompt injection through retrieval, into cross-tenant data access, into an agent action that exfiltrates the result. Testing each piece separately misses the chain entirely.
Questions to ask your security testing vendor
These questions separate vendors who have tested AI systems from vendors who added "AI" to their marketing page:
"Walk me through how you test for indirect prompt injection in RAG pipelines."
If they only describe direct injection, they test the easy case. If they ask about your retrieval architecture, chunking strategy, and metadata filtering before answering, they have done this before.
"How do you test cross-tenant data isolation in our specific vector database?"
This question cannot be answered generically. If they describe a methodology without first asking about your implementation, expect a generic test.
"What does your agent action abuse testing methodology look like?"
If they do not have one, they have not tested agentic AI. Agent architectures are growing fast and they present the most complex attack surface.
"Do you test model behavior under multi-turn manipulation?"
Single-turn injection catches the obvious stuff. Multi-turn drift is how capable adversaries work. If the vendor only tests single-turn, the hardest patterns go untested.
Red flags to watch for: a vendor who frames this as a scan, a vendor who runs a standard web app pen test with an "AI addendum" bolted on, a vendor who cannot describe indirect prompt injection without pulling up slides.
Building continuous testing
AI features change in ways traditional software does not. Models update when providers ship new versions, sometimes without notice. Prompts change when product iterates. Retrieval data changes every time a document is indexed or removed. Each change can introduce vulnerabilities that did not exist when you last tested.
A point-in-time test is a snapshot. You need the snapshot plus two ongoing layers.
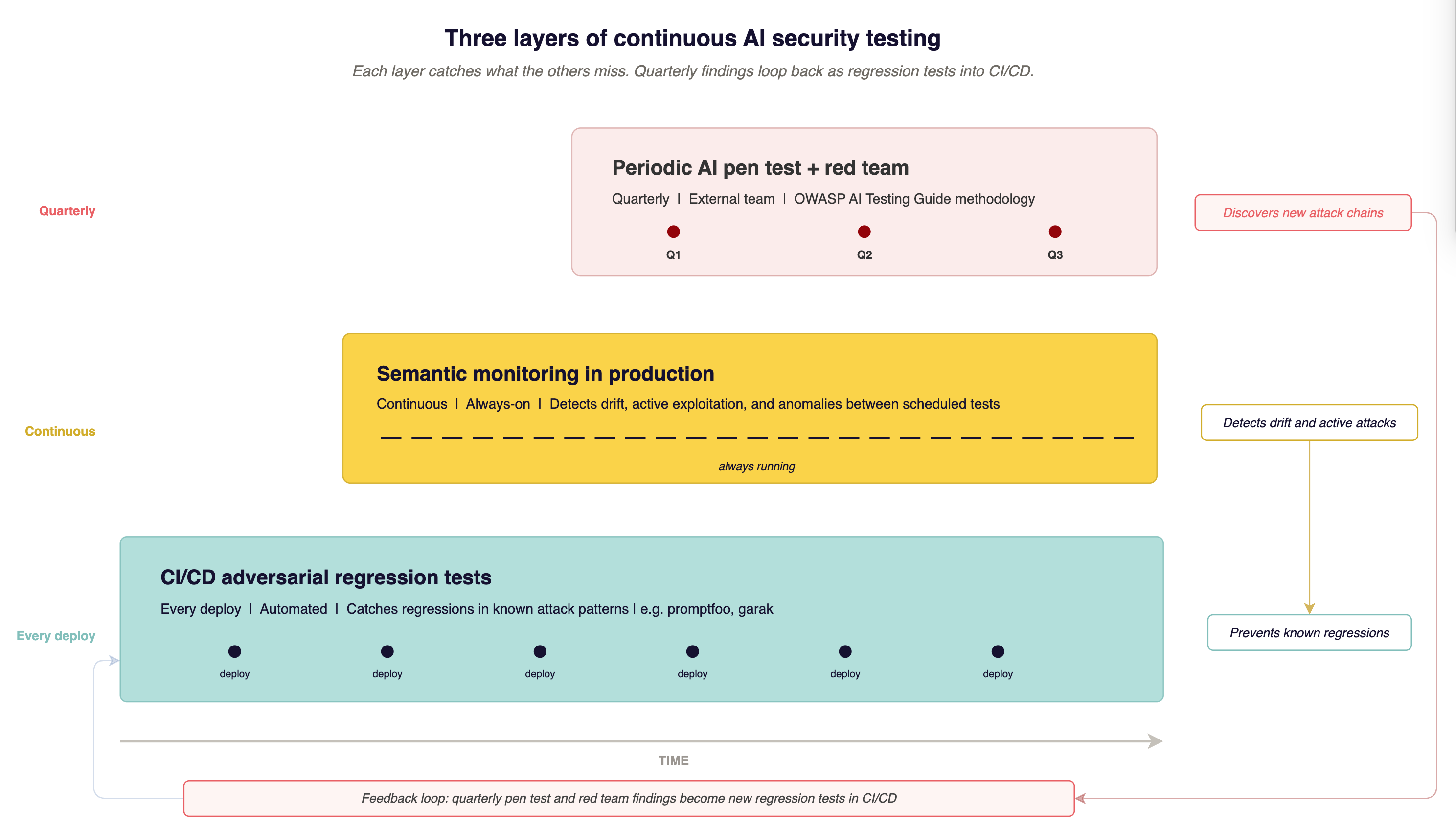
Adversarial regression tests in CI/CD
Your red team or pen test finds specific attack patterns that bypass your defenses. Turn those patterns into automated tests. Run them on every deployment. When the system prompt changes, when the guardrails update, when the retrieval pipeline changes, you find out immediately if something you already fixed is broken again.
promptfoo works for this. So does a custom harness built around the attack patterns specific to your system. The point is catching regressions, not discovering new vulnerabilities.
Semantic monitoring in production
Track what your model outputs over time. If your AI feature normally refuses out-of-scope requests at a consistent rate and that rate drops noticeably, something changed. A provider model update, a system prompt edit, or active exploitation.
Pre-deployment checks catch known problems. Production monitoring catches unknown problems and ongoing attacks. This is the layer between scheduled tests.
Periodic red team exercises
Quarterly or semi-annual, depending on how fast your AI features change. The AIUC-1 control (Part 4) calls for quarterly adversarial testing. Even without compliance pressure, the cadence matters because new AI attack techniques appear fast enough that quarterly is the minimum for staying current.
The three layers together: automated regression before deployment, semantic monitoring in production, adversarial red teaming on a schedule. Each catches what the others miss. No single layer covers everything.
Where you stand on TRACTION
The TRACTION framework maps security maturity into levels enterprise buyers recognize. For AI security testing:
L1, no AI-specific testing. The pen test covers the API endpoint. Nobody tested the model. This is where most companies sit. It is a defensible starting position only if you know the gap exists.
L2, manual testing before launch. Someone ran prompt injection tests before the feature shipped. No ongoing program. Better than L1, but the testing is stale if anything changed since launch.
L3, automated adversarial suite plus periodic red teaming. CI/CD runs regression tests for known AI attack patterns. An external team runs red team exercises on a regular schedule. You can show enterprise buyers that testing is ongoing.
L4, continuous monitoring plus CI/CD testing plus quarterly red team. Semantic monitoring in production. Automated regression on every deploy. Quarterly red team exercises covering the full attack chain. This is the maturity level where your testing program produces real evidence of continuous validation.
Most companies we work with are at L1. Getting to L2 takes a few days and no budget. L3 requires a tool and a testing vendor. L4 requires organizational commitment to AI security as ongoing operations.
Closing the series
This was the last article in a five-part series. Part 1 identified what kind of AI integrator you are and why it changes your risk profile. Part 2 covered architecture decisions that become permanent once production data flows through them. Part 3 separated security controls that work for AI from ones that do not. Part 4 showed how to document your architecture in terms auditors and enterprise buyers recognize. This article covered how to test whether any of it holds.
Read end to end, the series offers something most competitors in this space do not have yet: a working model for AI integration security. Not a checklist to follow, but a way to think about the problem that survives the next model update, the next framework revision, and the next enterprise buyer asking something nobody on the team has heard before.
The tooling will get better. The frameworks will solidify. The compliance requirements will get more specific. The underlying pattern will not change: build deliberately, test meaningfully, document what is true.
If enterprise buyers are asking questions about your AI features that you cannot answer yet, we can help. We build the security architecture and testing program that makes those answers honest, and we test it the way this article describes.



