

You're building an amazing AI-enabled product, your team picked a model provider right away, the RAG pipeline looked good after a whiteboard session, the vector database is provisioned, and embeddings are flowing. Everyone and their AI-copilot are building the app.
Later this year, an prospective customer will ask how you protect their data from others in your vector store, and your CTO will realize the answer is "we kind of do, but we don't, really." The architecture rewrite to fix it will take some months. And the buyer will not wait.
We see this pattern in AI security assessments. A team ships a working AI feature in short order. The architecture is clean and the demo works. And then the security questionnaire arrives with a section on AI governance nobody has seen before, and the team discovers that half of their architecture decisions cannot be changed without a rewrite, and their GRC platform didn't yet mention that and how do answer these things.
That gap, between the whiteboard session where everything looked straight-forward and reversible and the deal where you discover it was not, is what this article is about.
This is Part 2 of "So You Want to Add AI Into Your App." Part 1 covered how to recognize whether you are a consumer, integrator, or trainer. If you are building AI into your product and customer data touches the model, you are an integrator. This article covers the architecture decisions you are making right now that will be hardest to change later.
Three kinds of doors
Amazon uses a decision framework that applies well to AI architecture.
Two-way doors are reversible with moderate effort. Model provider selection is a two-way door. Orchestration framework choice is a two-way door. Make these fast. Do not form a committee.
One-way doors are mostly irreversible without major rework. Permission model shapes, training on customer data, data residency commitments. If you need to change one of these after launch, you are looking at considerable amounts of work. It pays to get these right before you ship.
Trapdoors look like two-way doors in planning and become one-way doors once production data starts flowing through them. RAG tenant isolation model, embedding storage locations, vector database choices. It's risky to assume these can be fixed easily later. They cannot, not without significant rework.
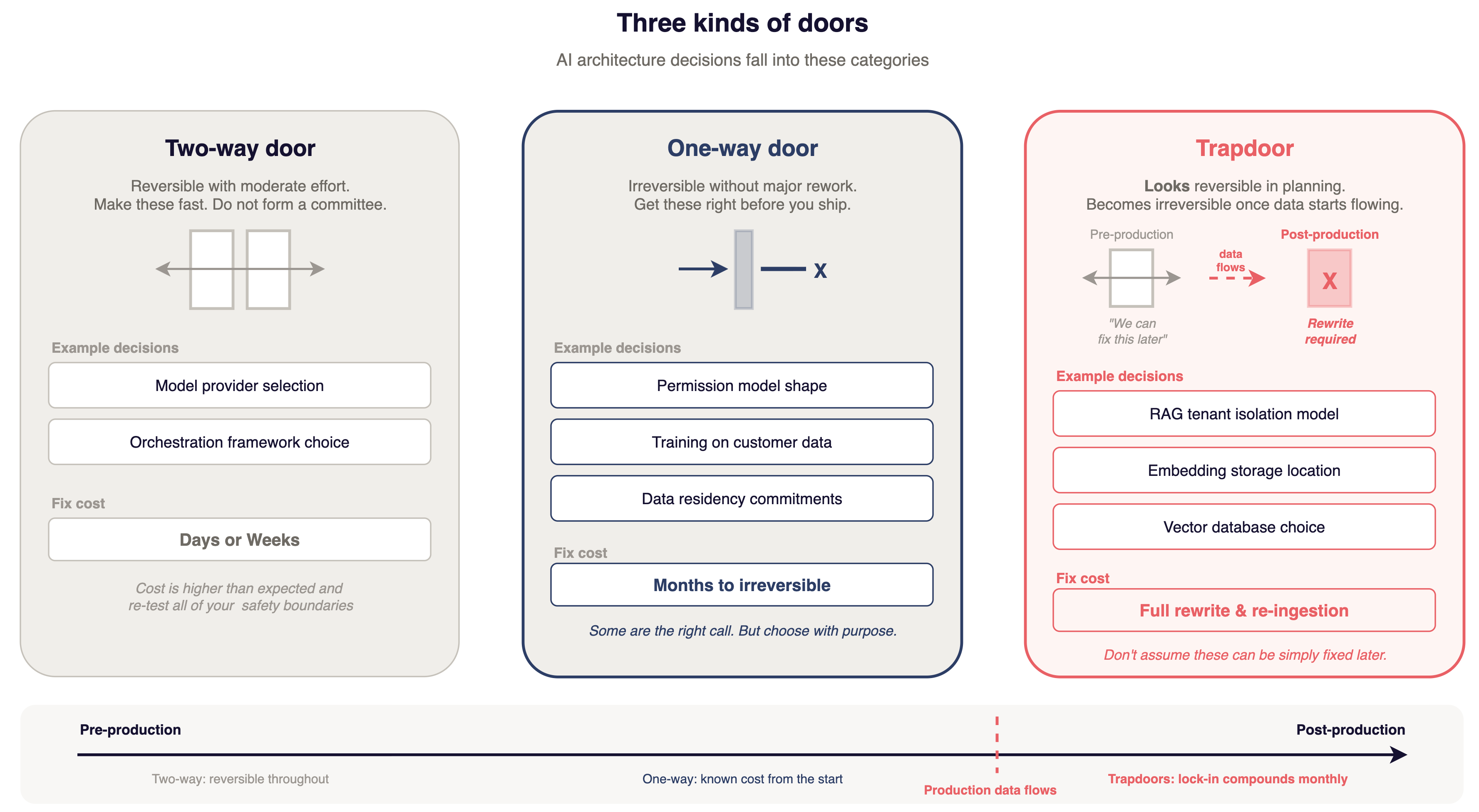
You do not need to avoid one-way doors. Some are the right call. You should recognize them so you choose on purpose.
Model provider coupling
The API is the easy part. OpenAI, Anthropic, and Bedrock have similar REST interfaces. Switching the HTTP call is a day of work.
The lock-in lives everywhere else.
For example, prompt libraries are tuned to one model's safety behavior. Claude, ChatGPT, and Gemini handle instruction hierarchy and refusal patterns slightly differently. Switch models and your safety boundaries may change. The prompts will run but they may not refuse the inputs they you expect.
Your evaluation pipelines are calibrated to expected outputs. Switch the model and every baseline shifts. You go from swapping a provider to re-establishing what "correct" and "safe" mean.
If you fine-tuned, those weights probably live on the provider's infrastructure without an export button. If you fine-tuned for safety compliance in a sensitive domain, you get to start over.
Function calling formats differ across providers. Context window assumptions are baked into your chunking strategy. Every provider-specific feature in a security-critical path is a spot that should be revalidated.
Bedrock offers an abstraction layer that lets you swap underlying models without rewriting integration code, but the tradeoff is AWS lock-in and slower model availability. Bedrock may not offer the latest model version for weeks or months after direct API access does. If your feature depends on a capability only available in the newest release, the abstraction layer becomes a constraint.
Here is a concrete way to measure your coupling. Search your codebase for provider-specific imports, model name strings, and hardcoded context window values. If the count is relatively low, you are loosely coupled. If it is relatively high, swapping providers is a real project, not a straightforward task.
This is a two-way door, but the cost of walking back is higher than you might expect. The API swap is trivial but re-testing safety boundaries can take days or weeks.
Data architecture
Model provider coupling is annoying to reverse. Data architecture decisions create attack surface you live with for much longer. Several decisions important considerations follow.
Where embeddings live
Your VPC versus Pinecone versus Weaviate Cloud versus pgvector. It looks like an infrastructure choice, but it's also a data sovereignty decision.
Embeddings are a compressed representation of your customers' sensitive data. Where they live determines who has physical access, what network boundaries protect them, what jurisdiction governs them, and what happens if the provider is compromised. Their breach is your breach. Their insider threat is your insider threat - especially from a regulatory perspective.
Once you have millions of embeddings in production, migration means re-embedding everything. Compute cost, downtime, behavioral changes if you switch embedding models. Every month adds more embeddings and deepens the lock-in.
When an enterprise prospect asks "where does our data live?" and the answer includes a vector database SaaS you might not mention in your DPA, and their security team see that. Don't say "all data hosted in AWS us-east-1" but the vector database is a separate SaaS provider in a different region.
Multi-tenant isolation in RAG
This is the most consequential architecture decision most AI integrators make. It is also the one most often made by default.
An attacker evaluating your AI feature asks one question: can I get data I should not have access to? The answer depends on your isolation model.
A common pattern is a shared index with metadata filtering. One vector store for all tenants. Each document chunk gets a tenant_id metadata field. At query time, every retrieval call includes a filter to scope results to the requesting tenant.
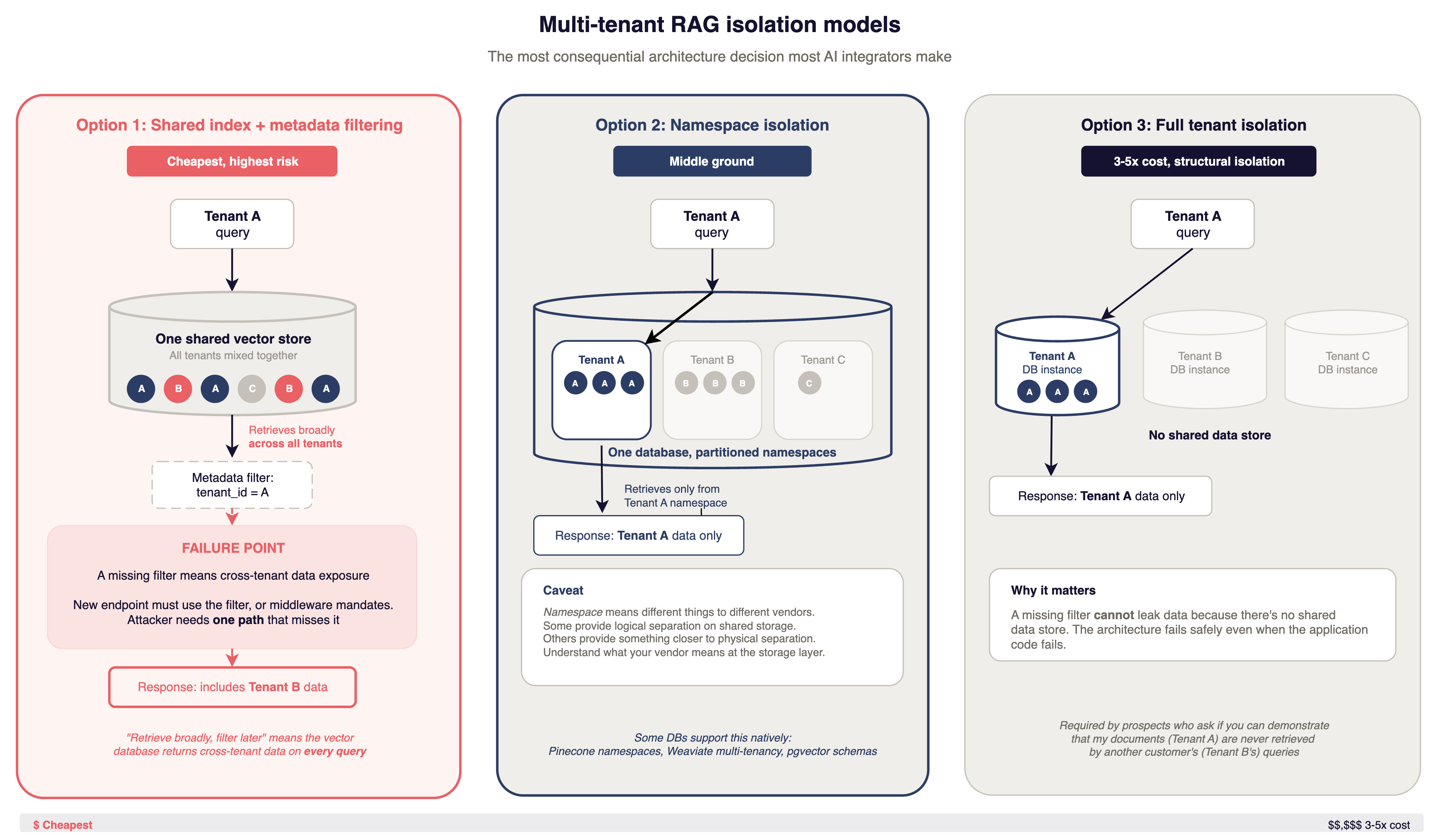
There are two variants, and they fail differently. In pre-filter mode, the vector database applies the tenant_id constraint during the ANN (Approximate Nearest Neighbor) search itself. Done correctly and routed through a single enforced query builder, this is a defensible pattern for many threat models. The failure mode is operational: every query path must include the filter, every new endpoint must remember it, and the attacker needs one path that misses it. One developer adding a feature. One edge case. One code path that skips the standard query builder.
Post-filter mode is structurally worse. The vector database returns cross-tenant data on every query and the filter hides it from the response. If the filter fails, the data was already retrieved. The system accessed data it should not have. The filter was the only thing between that data and the user. Check which mode your vector store is actually running in before treating metadata filtering as your isolation boundary.
Security researchers have described multi-tenant RAG isolation as "the industry's Code Red." There is no standard pattern across vector stores, and vendors use inconsistent terminology for their isolation features.
Namespace or collection isolation is better. Pinecone namespaces, Weaviate multi-tenancy, pgvector schemas. But "namespace" means different things to different vendors. Some provide logical separation on shared storage. Others provide something closer to physical separation. Understand what your vendor means at the storage layer before treating it as a security boundary.
Full tenant isolation, separate database instances per tenant, costs multiple times more, but the isolation is structural. A missing filter won't leak data because there is no shared data store. The architecture fails safely even when the application code fails.
The trapdoor works like this: you start with a shared index because it's simple and cheap. Six months later a prospect wants provable isolation, or an assessment finds cross-tenant retrieval is possible. Retrofitting structural isolation means re-ingesting all data per tenant, rerouting every retrieval path, updating every integration point. Teams describe this as a multi-month project that blocks other development.
Many companies use RAG instead of fine-tuning, and most started with shared indexes. The ones selling to enterprise customers are finding out what the cheap choice costs. One common trigger: the company passes a SOC 2 audit that does not probe AI-specific controls, then an enterprise buyer's security team asks "can you demonstrate that my documents will never be retrieved during another tenant's queries?" and the honest answer is no, not structurally. That SOC 2 badge gets you to the conversation. It does not get you through it.
Customer data in training pipelines
Once model weights absorb customer data, the effects are permanent. Machine unlearning is a research topic, not a production tool. There is no method to remove a specific customer's influence from model weights.
A malicious document in your training data creates permanent effects. You cannot remove its influence from the weights.
A customer exercising their right to erasure under GDPR or CCPA expects deletion. You can delete the training data. You cannot delete what the model learned from it.
Either you never train on customer data, or you accept permanent influence, permanent attack surface, and a permanent compliance gap. Decide before the first training run. Make sure a lawyer is in the room.
Many companies avoid this problem by using RAG instead of fine-tuning. RAG keeps customer data in a retrieval layer separate from the model. The model does not learn from it. Deletion is a database operation, not a research problem. If you are considering fine-tuning on customer data, ask what happens when Customer X churns and requests deletion of everything. If the answer involves retraining the model from scratch, you should weigh that cost against the performance improvement fine-tuning gives you.
Privacy decisions that compound
Each one is manageable alone but together they create a compliance surface that hardens over time.
Data residency: which regions do inference calls route through? If you serve EU customers and inference routes through US infrastructure, you have a compliance problem. OpenAI, Anthropic, and Bedrock handle routing differently. Do not assume.
Data retention at the provider: what happens to prompts after inference? Logged? For how long? Accessible to provider employees? Shorter retention means a smaller window if the provider is compromised. Get the terms in writing, e.g. a DPA and compare them to your privacy policy.
Conversation logs are PII processing. Prompts contain customer data, often the data customers care most about. Your DPA should cover it. Your data processing inventory should include it.
Once data flows are established to a provider in a specific region with specific retention terms, changing anything could require contract renegotiation, architecture changes, and possibly customer re-consent.
The EU AI Act high-risk enforcement starts August 2026. Colorado's AI Act takes effect June 2026 and applies to any company serving Colorado customers, not just Colorado-based ones. Both carry real penalties. EU AI Act non-compliance penalties can reach up to 7% of global revenue. If your architecture has not accounted for these deadlines, the window is months, not years. These are both undergoing evaluation today but the will influence decisions tomorrow, regardless of their final language.
The compounding effect is important - once you pick a provider, a region, and a retention policy, those choices spread into your DPA, your privacy policy, your SOC 2 documentation, and your enterprise customer contracts. Changing any one element later means updating all of them. Each AI feature you add and each new market you enter creates more dependency on those original choices. The compliance surface does not just grow. It hardens.
Permission model shape
Tenant isolation is only half of the retrieval story. Within a tenant, users still have different permissions. If a user on a basic role can prompt the model into retrieving documents only admins should see, tenant scoping did its job and the permission model still failed. Retrieval has to respect the requesting user's ACLs, not just their tenant_id.
Enforce per-document permissions at query time, or bake them in when you build the index. The failure mode is quiet - the model answers helpfully using content the user could not have opened directly, and nobody notices until an auditor asks.
Most teams fall into a permission model by default. The default is static permission grants: the AI feature has fixed permissions to, e.g.: Read all customer documents, Query the database, Generate responses. Same access regardless of what it is asked to do.
The problem with static permissions is blast radius. If the AI feature has read access to all customer documents (because it might need any of them to answer a question), then a prompt injection that hijacks the model also has read access to all customer documents. The blast radius of any exploit equals the total permission scope.
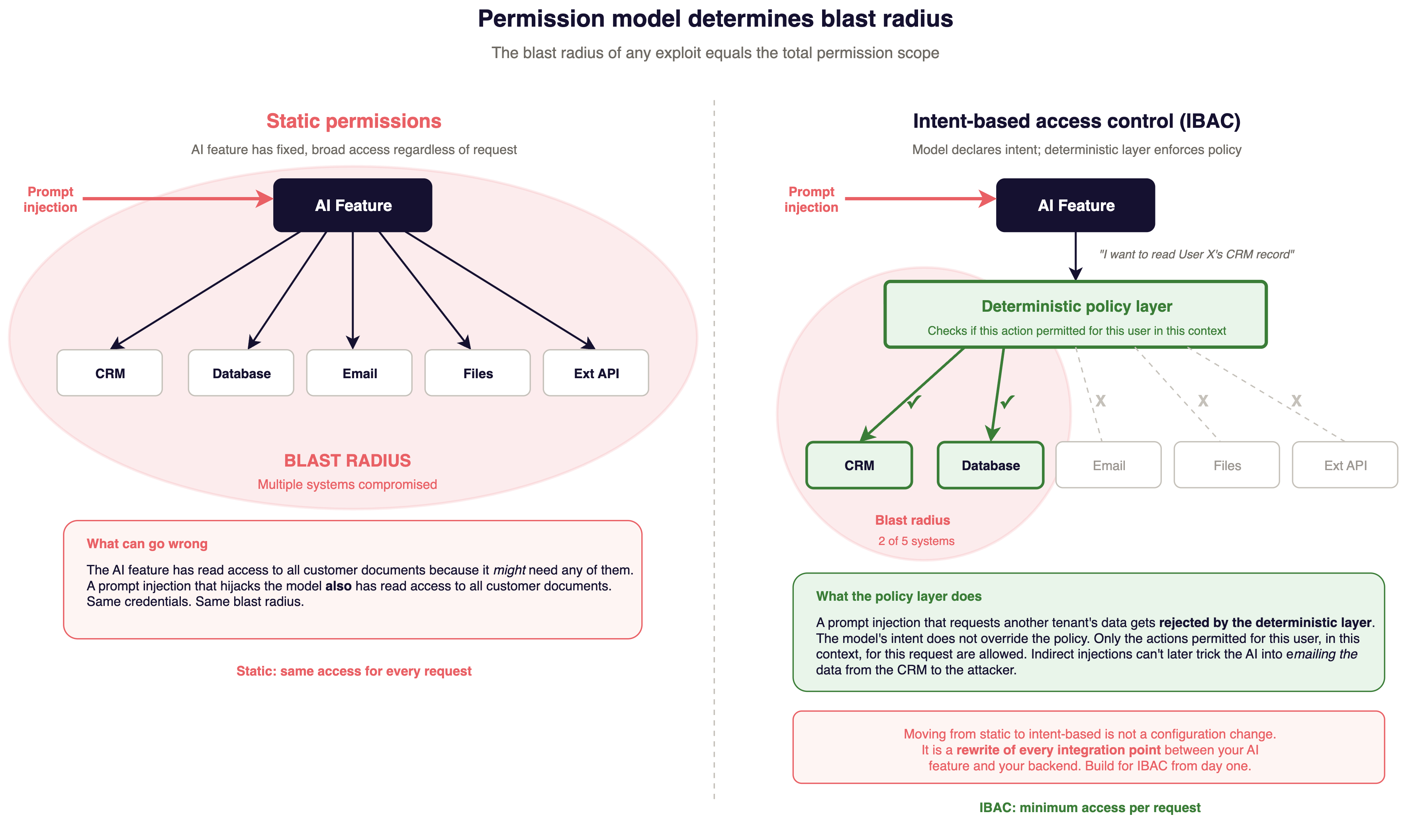
Intent-based access control (or user-delegated permissions) works differently. The model declares what it wants to do. A deterministic layer checks whether that action is permitted for this user in this context. A prompt injection that requests another tenant's data sent to the attacker gets rejected by the deterministic layer. The model's intent does not override the policy.
The AI service exchanges the requesting user's session token for a downscoped credential before every tool call. Tool endpoints enforce authorization on that credential, not on the AI service's identity. If the model asks to read Document 47, the retrieval tool checks whether this user can read Document 47, using the same authorization logic that protects the rest of your application. The AI feature has no standing privileges of its own. Classical computer science calls the failure you are preventing the confused deputy problem: a privileged service acting on behalf of a less-privileged caller without carrying the caller's authority check.
The cost of moving from static to intent-based access control depends on where you start. If your application already propagates user identity on every request, plumbing it through to tool calls is mechanical work. If your AI service runs as a shared principal holding the union of every user's permissions, switching means rebuilding every integration point between the AI feature and your backend.
If you think you will ever need agents, action-taking features, or variable-scope data access, build for intent-based access control from day one. The engineering cost is front-loaded. Starting with static permissions and migrating later is a rewrite.
A practical test: look at the OAuth scopes or API credentials your AI feature uses. Do they grant access to multiple tool calls, with external connectivity, with sensitive data access? If prompt injection succeeded against your AI feature right now, could it access resources the requesting user cannot access directly in your app? And if the credential can access all tenants, your permission model is static regardless of what your application code does. The credential is the real boundary, not the code that uses it.
Build, integrate, or orchestrate
Every handoff in your AI pipeline is a trust boundary. Every trust boundary is a place where isolation, access controls, and logging can fail.
Building your own retrieval stack means you control every boundary. Maximum control, maximum engineering cost.
A managed RAG service means trusting their security model. Their multi-tenancy, their access controls, their patching timeline. If they get breached, you explain it to your customers.
An orchestration layer like LangChain or LlamaIndex puts a dependency in the most sensitive part of your data path. In late 2024 and early 2025, researchers discovered multiple vulnerabilities across MCP implementations in AI coding tools, producing dozens of CVEs. If your production feature depends on an orchestration framework, their vulnerabilities are yours. Your patching timeline depends on their release cycle, not your security team's urgency.
The orchestration layer also obscures the data path. When your application calls a LangChain retrieval chain, the framework handles vector database queries, prompt construction, and model API calls internally. If an enterprise buyer asks "what data is included in prompts sent to the model?", you need to understand what the framework does at each step. If a security assessor asks "where does tenant scoping happen in the retrieval path?", the answer may be buried in framework internals you did not write and may not fully understand.
For each handoff in your AI pipeline, ask a few questions. Who controls this component? What happens when this component is compromised? Can I get a security advisory within 24 hours of disclosure? If you do not know the answer to the third question, you have a gap in your incident response that an attacker can exploit.
This isn't to say not to use those services - but to understand the implications of using them.
The spectrum matters for another reason: it affects your ability to answer the architecture questions enterprise buyers ask. A buyer asking "how does our data move through your AI pipeline?" expects a specific answer. If half of that pipeline is a third-party framework, you'll need additional assurances.
Decision matrix
For AI architecture decisions your team has made or is about to make:

For every trapdoor and one-way door in this table, someone at your company should be able to explain why it is classified that way. If nobody can, you have found your next architecture discussion.
Where you are on TRACTION
TRACTION is an enterprise security readiness framework with an AI/ML maturity dimension. Most companies shipping AI features are at the L2-to-L3 boundary.
At L2, the shared vector index works. Static permissions work. Nobody asks hard questions about your architecture.
At L3, the security questionnaire has AI-specific sections. The buyer asks about tenant isolation, data residency, and model governance. Your architecture decisions support credible answers or they do not.
The trapdoors in this article close during the L2-to-L3 transition. If you are there now, audit your decisions against the matrix before the next enterprise review. The self-assessment at traction.fyi covers AI/ML maturity alongside five other dimensions. It takes about fifteen minutes and tells you where the gaps are before a buyer finds them.
What to do before your next sprint
Ordered by what an attacker would exploit first.
Audit your RAG tenant isolation. If you use a shared vector index, list every code path that queries the vector database. Verify each one enforces tenant scoping. Have someone who did not write the code do the review. The developer who built it might just assume it works.
Map data flows from the attacker's perspective. For every AI feature, trace customer data from your application through the inference endpoint and back. Where does it leave your infrastructure? What retention applies? What happens if the provider is compromised? If you cannot draw this in fifteen minutes, you cannot answer when an enterprise buyer asks. They will ask. The architecture questions enterprise buyers ask covers what to prepare for.
Classify your open decisions and use the above matrix. For trapdoors and one-way doors, decide whether the current architecture is an accepted risk or an unintentional one. Accepted risk means someone is watching the gap. Unintentional risk means nobody is.
Part 3 covers which existing security controls work for AI integrations and which ones were designed for a different threat model.
Series: So you want to add AI into your app
- Part 1: Three types of AI integration, and why only one of them is your problem
- Part 2: The decisions you can't undo (this article)
- Part 3: Which of your existing security controls still work and which do not
- Part 4: What your auditor will expect and what actually matters for compliance
- Part 5: How to test systems that do not produce the same output twice
Part 2 of "So You Want to Add AI Into Your App." Adversis works with SaaS companies shipping AI features to build security architecture that survives enterprise buyer scrutiny. AI red teaming, prompt injection testing, compliance readiness for the frameworks that apply to integrators. If you want to understand your exposure before a buyer asks, we should talk.



